
The way Facebook processes what the world writes is about to get a bit more cosmopolitan.
As Facebook’s scope continues to grow globally, the way it rolls out features has been complicated by the fact that there are more than 100 languages currently supported on the site. When it comes to building text boxes that users can type status updates into, this isn’t that difficult of a problem, but as artificial intelligence continues to drive everything Facebook does, the challenges skyrocket for ensuring that its systems fully grasps what its users are wanting.
The company’s Applied Machine Learning team has spent the past year working on a technology called multilingual embeddings which it says could significantly improve the speed at which its natural language processing tech is able to operate across foreign languages. In early tests, the new process is 20-30X faster than previous methods, the company said.
Beyond reductions in latency, the tech could help future Facebook features reach more people more quickly and ensure a lot more consistency across what services the website offers across the globe
“From the multilingual understanding perspective, I want everybody to use all the features that are deployed by Facebook in their own language,” Facebook head of translation Necip Fazil Ayan told TechCrunch in an interview. “This should not be limited to a particular language, but we want to move to a world where all features are available everywhere, and can be used by everybody.”
The company has already been utilizing the tech over the past several months to detect content-policy violations, surface M Suggestions in Messenger and power its Recommendations feature across several languages. Facebook has about 20 engineers inside its AML group working on the language and translation technologies.
Word embeddings are essentially vectors that allow text classifiers to approach human language in a more context-driven way, highlighting the interrelatedness of words to eventually derive shared meaning or intent. (Here‘s a good breakdown if you’re curious.) Companies like Facebook can make (and have made) word embeddings for individual languages, but it’s pretty labor intensive to gather the training data for classifiers when you’re dealing with more than 100 languages FB supports, thus they’ve had to work towards a more scalable approach.
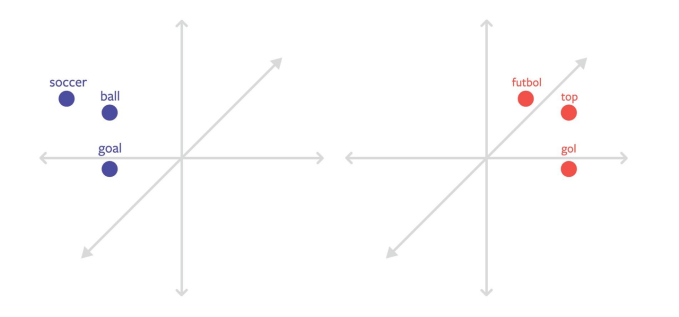
Simplified sample word embeddings highlighting separate word vectors in Spanish and English for “soccer”
Previously it’s led to the company essentially translating foreign languages to English and then running English classifiers on them, but this has been a rough solution due to translation errors, but perhaps more importantly the solution has been far too slow. By mapping multiple languages onto similar word vectors, a blog post from the company details, Facebook’s method “can train on one or more languages, and learn a classifier that works on languages you never saw in training.”
Even with the 20-30 significant reduction in latency, Facebook says that this approach is seeing results similar to what it would be getting with language-specific classifiers in some early testing.
The company’s work is still in its early stages when it comes to language support, right now feature rollouts utilizing the tech support French, German and Portuguese though Ayan says that internally the team has been investing in tech that works in the “tens of languages.” Furthermore, the group is working to improve accuracy by building up sentence and paragraph embeddings that get to the root intent of a body of text even more quickly.
Featured Image: Sean Gallup/Getty Images
Lucas Matney
http://feedproxy.google.com/~r/techcrunch/facebook/~3/hSQglxNKOmk/
Source link


