PipelineAI
https://www.meetup.com/Advanced-Spark-and-TensorFlow-Meetup-New-York/events/259179950/
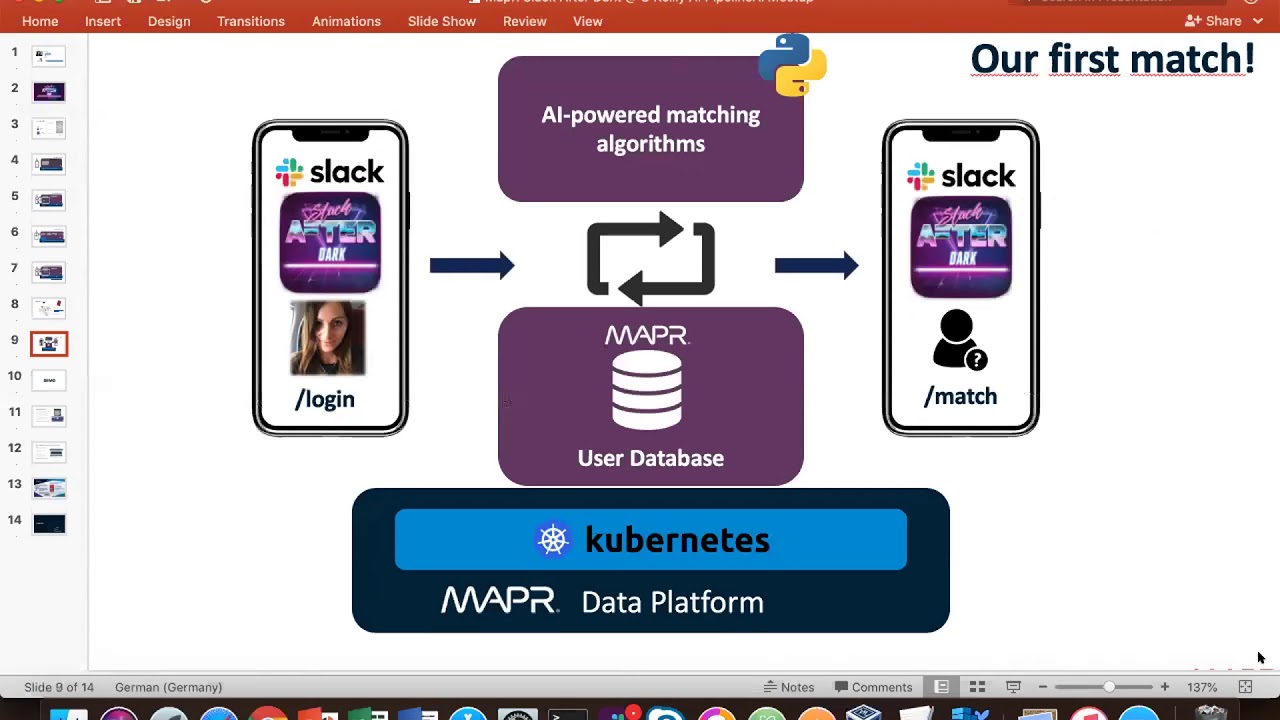
Talk 1: “Slack After Dark”: Realtime ML + Kubernetes + TensorFlow + MLflow + Slack API + PipelineAI (Antje Barth, Developer Advocate, MapR)
Welcome to “Slack after Dark” – our slack-based dating app which showcases an end-to-end containerized & integrated ML workflow, running Online Model Predictions and Online Model Training using Keras/Tensorflow, PipelineAI, MapR Data Platform and Slack!
In this talk and live presentation you’ll also see how a streaming architecture can help you with moving from batch to real-time model training, and simplifying your overall model data logistics.
Antje will cover a lot of topics from this blog post: https://medium.com/@PipelineAI/slack-after-dark-by-pipelineai-ba2ec2397c3a (https://www.youtube.com/watch?v=kuiUSXniDaI)
Speaker Bio:
Antje Barth works as a Developer Advocate at MapR. She’s responsible for creating demos that show how the latest technology trends in ML/AI, cloud and container technologies can integrate and benefit from a modern dataware layer. Here is her LinkedIn: https://www.linkedin.com/in/antje-barth/
Before joining MapR, Antje worked as a Systems Engineer in the Data Center team at Cisco, and adding 10 years of experience in Data Center and Cloud technologies to her Big Data knowledge.
Talk 2: Real-Time, Continuous ML/AI Model Training, Optimizing, and Predicting with Kubernetes, Kafka, TensorFlow, KubeFlow, MLflow, Keras, Spark ML, PyTorch, Scikit-Learn, and GPUs (Chris Fregly, Founder @ PipelineAI)
Chris Fregly, Founder @ PipelineAI, will walk you through a real-world, complete end-to-end Pipeline-optimization example.
Through a series of live demos, Chris will install, create, and deploy a model ensemble using the PipelineAI Platform with GPUs, TensorFlow, and Scikit-Learn.
While most Hyper-parameter Optimizers stop at the training phase (ie. learning rate, tree depth, ec2 instance type, etc), we extend model validation and tuning into a new post-training optimization phase including 8-bit reduced precision weight quantization and neural network layer fusing – among many other framework and hardware-specific optimizations.
Next, we introduce hyper-parameters at the prediction phase including request-batch sizing and chipset (CPU v. GPU v. TPU). We’ll continuously learn from all phases of our pipeline – including the prediction phase. And we’ll update our model in real-time using data from a Kafka stream.
Lastly, we determine a PipelineAI Efficiency Score of our overall Pipeline including Cost, Accuracy, and Time. We show techniques to maximize this PipelineAI Efficiency Score using our massive PipelineDB along with the Pipeline-wide hyper-parameter tuning techniques mentioned in this talk.
Bio
Chris Fregly is Founder and Applied AI Engineer at PipelineAI, a Real-Time Machine Learning and Artificial Intelligence Startup based in San Francisco.
He is also an Apache Spark Contributor, a Netflix Open Source Committer, founder of the Global Advanced Spark and TensorFlow Meetup, author of the O’Reilly Training and Video Series titled, “High Performance TensorFlow in Production with Kubernetes and GPUs.”
Previously, Chris was a Distributed Systems Engineer at Netflix, a Data Solutions Engineer at Databricks, and a Founding Member and Principal Engineer at the IBM Spark Technology Center in San Francisco.
Here is his LinkedIn: https://www.linkedin.com/in/cfregly
https://youtube.pipeline.ai
https://slideshare.pipeline.ai
Source


