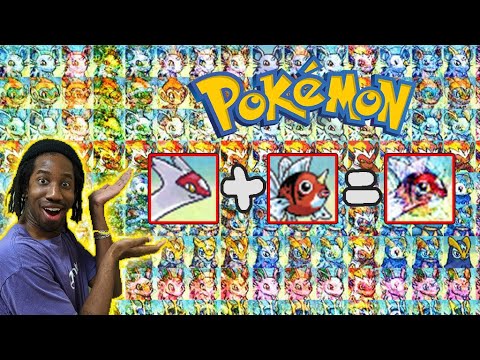
Jabrils
WATCH PART 1: https://www.youtube.com/watch?v=2XdbQ0tiaN0&list=PL0nQ4vmdWaA0K6WQq6X-tP6n7tovJVomX
Pokemon Dataset: https://www.kaggle.com/brilja/pokemon-mugshots-from-super-mystery-dungeon
http://jabrils.com/pokeblend
SUBSCRIBE FOR MORE: http://sefdstuff.com/science
SUPPORT ON PATREON: https://www.patreon.com/Jabrils
JOIN DISCORD: https://discord.gg/qgaahvc
Please follow me on social networks:
twitter: http://sefdstuff.com/twitter
instagram: http://sefdstuff.com/insta
reddit: https://www.reddit.com/r/SEFDStuff/
facebook: http://sefdstuff.com/faceb
REMEMBER TO ALWAYS FEED YOUR CURIOSITY
Source



I feel like this is just two pokemon pics layed on top of each other with one having very low opacity.
i can help you with gathering dataset
I think the issue is that you are computing cost by the pixel difference. In this case it makes sense that the neural net will just overlay the images on top of each-other. With your current setup, you could make an optimization algorithm which, given 2 pokemon, progressively produces a pixel representation of a pokemon which minimizes the distance between the hybrids encoded feature vector and the 2 provided feature vectors.
For some reason, Pokemon irritates the shit out of me.
9:21
Imagine someone logs onto his computer and they find 5000 pictures of Pokémon 😂😂😂
hmmm
If you're trying to draw a pokemon in the style of another, you could maybe check if neural style transfer could be applicable/give you the results you're looking for. Instead of a vector, you combine the "style" of one with the "structure" of the other.
You need to set it to W for Wumbo
I have an idea for a fighting game where every time you open the game, different AI encoders make whole new images for fighters, sounds, stages, a new game icon, etc.
that chartle is CURSED
Did you try data augmentation? You can randomly rotate, zoom in, etc….to get different variations of photos. I know you're using autoencoding and its a bit different from a CNN take of things but if you could do something like this to generate more "pokemon" with your current dataset theres a possibility you could increase the efficiency of your model.
It is called an alolan Pokémon! Not an aloha Pokémon!
That ff7 music tho
Chartle is fucking horrific.
Chartle is fucking horrific.
Update when???
What is the music at 7:15? I recognize it, should know it and it's driving me crazy not knowing what it is
Just did a quick scroll and didn't see this mentioned
It'd be sick if you hooked this up to an adversarial network that detects fake pokemon from real ones, similar to how current image combining networks are set up. If the adversarial network gets good enough to determine fake from real, then the image combining network needs to develop new logic to produce more convincing images.
I know that's like a whole other project in itself, but still I think it'd be worth the effort. 🙂
Congratulations, you have successfully created a worse version of an opacity slider.
Good effort, but this has already existed https://pokemon.alexonsager.net/
what if you removed the back grounds of the 500 pics? would it lead to better blends?
Those early sheets look like tabs of acid lol
As the top comment already mentions, this is literally a glorified photoshop tool that overlays a slightly transparent pokemon on another…
Work on the black lines and outlining
I think your smaller input size worked out better because you had more consistent data;Like 1 picture per Pokemon, each Pokemon facing the same direction, having the same facial expression, and so on. This will give you a more consistent output, but less variation in your AI's ability to create new Pokemon. Yes you do need a lot of data to make a really immersive AI but the data needs to be concise, and cataloged well so your program knows what its working with. Overall i think these results were still really impressive though!
what , why the vid stoped soo suddenly :v
13:13 Nigel Thornberry
Is it the comparison is currently a linear function but a logarithmic function would yeild better results from the dataset?
I would like to have your code 🙁
I'd use the MD portraits from Bulbagarden Archives. They're practically already labeled.
https://archives.bulbagarden.net/wiki/Category:Mystery_Dungeon_portraits
Would it be helpful if each pokemon was broken down into smaller feature groups. Like eyes, mouths, ect. Maybe this way the encoder has something more specific to translate.
Why do your videos just cut off at the end please stop
2 questions:
– Did you try forcing a smaller bottleneck in the AutoEncoder?
– Is your encoder 100% linear? (I think you should merge the latent space, not the input)
Trozei!!!
Double your input set by flipping them all horizontally.
I guess you haven't figured out imagenet??? It does a good job at dialing in the weights and biases before training so that you might have a better chance of obtaining structures that matter
Why dont split image with kmeans or fuzzy c means by color and/or morphological and enter in neural network?
https://ibb.co/gFzVL7z
https://ibb.co/87ksd16
Dude, you're probably not gonna see this but what about using a variational auto-encoder? Or DCGAN?
Why not GANs?
I know your probably not going to see this but, what if you make the AI detect curtain important features, such as a nose, eyes, mouth, ears, etc. and have the program cut out those to make a combination, and also allow for what the dominant color is on the Pokmen. I know almost nothing about programming and machine learning but, it’s a thought
You know , you should make an application that allows youtube creators to edit their content without having to do it themselves. The app can do it o the basis of the category of subject.
Why did you train the model 1000 times? It doesn't make to over-thinking?
How many hours it takes from you?? He he he he