Jay Alammar
Canonical Correlation Analysis is one of the methods used to explore deep neural networks. Methods like CKA and SVCCA reveal to us insights into how a neural network processes its inputs. This is often done by using CKA and SVCCA as a similarity measure for different activation matrices. In this video, we look at a number of papers that compare different neural networks together. We also look at papers that compare the representations of the various layers of a neural network.
Contents:
Introduction (0:00)
Correlation (0:54)
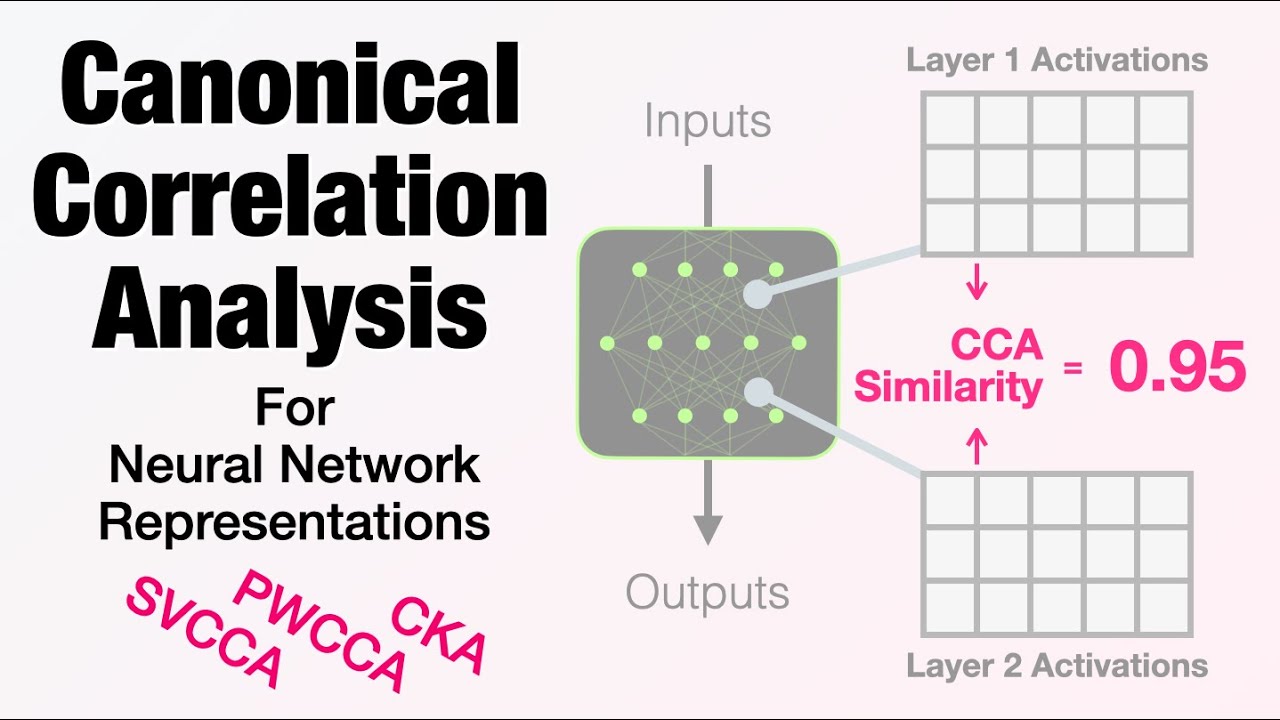
How CCA is used to compare representations (2:50)
SVCCA and Computer Vision models (4:40)
Examining NLP language models with SVCCA: LSTM (9:01)
PWCCA – Projection Weighted Canonical Correlation Analysis (10:22)
How multilingual BERT represents different languages (10:43)
CKA: Centered Kernel Alignment (15:25)
BERT, GPT2, ELMo similarity analysis with CKA (16:07)
Convnets, Resnets, deep nets and wide nets (17:35)
Conclusion (18:59)
Explainable AI Cheat Sheet: https://ex.pegg.io/
1) Explainable AI Intro : https://www.youtube.com/watch?v=Yg3q5x7yDeM&t=0s
2) Neural Activations & Dataset Examples https://www.youtube.com/watch?v=y0-ISRhL4Ks
3) Probing Classifiers: A Gentle Intro (Explainable AI for Deep Learning) https://www.youtube.com/watch?v=HJn-OTNLnoE
—–
Papers:
SVCCA: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability
https://arxiv.org/pdf/1706.05806.pdf
Understanding Learning Dynamics Of Language Models with SVCCA
https://arxiv.org/pdf/1811.00225.pdf
Insights on representational similarity in neural networks with canonical correlation
https://arxiv.org/pdf/1806.05759.pdf
BERT is Not an Interlingua and the Bias of Tokenization
https://www.aclweb.org/anthology/D19-6106.pdf
Similarity of Neural Network Representations Revisited
http://proceedings.mlr.press/v97/kornblith19a/kornblith19a.pdf
Similarity Analysis of Contextual Word Representation Models
https://arxiv.org/pdf/2005.01172.pdf
Do Wide and Deep Networks Learn the Same Things? Uncovering How Neural Network Representations Vary with Width and Depth
https://arxiv.org/pdf/2010.15327.pdf
—–
Twitter: https://twitter.com/JayAlammar
Blog: https://jalammar.github.io/
Mailing List: http://eepurl.com/gl0BHL
——
More videos by Jay:
The Narrated Transformer Language Model
https://youtu.be/-QH8fRhqFHM
Jay’s Visual Intro to AI
https://www.youtube.com/watch?v=mSTCzNgDJy4
How GPT-3 Works – Easily Explained with Animations
https://www.youtube.com/watch?v=MQnJZuBGmSQ
Up and Down the Ladder of Abstraction [interactive article by Bret Victor, 2011]
https://www.youtube.com/watch?v=1S6zFOzee78
The Unreasonable Effectiveness of RNNs (Article and Visualization Commentary) [2015 article]
https://www.youtube.com/watch?v=o9LEWynwr6g