Nicholas Renotte
Want to get your hands on GPT3 but cbbd waiting for access?
Need to kick off some AI powered text gen ASAP?
Want to write a love song using AI?
I got you!
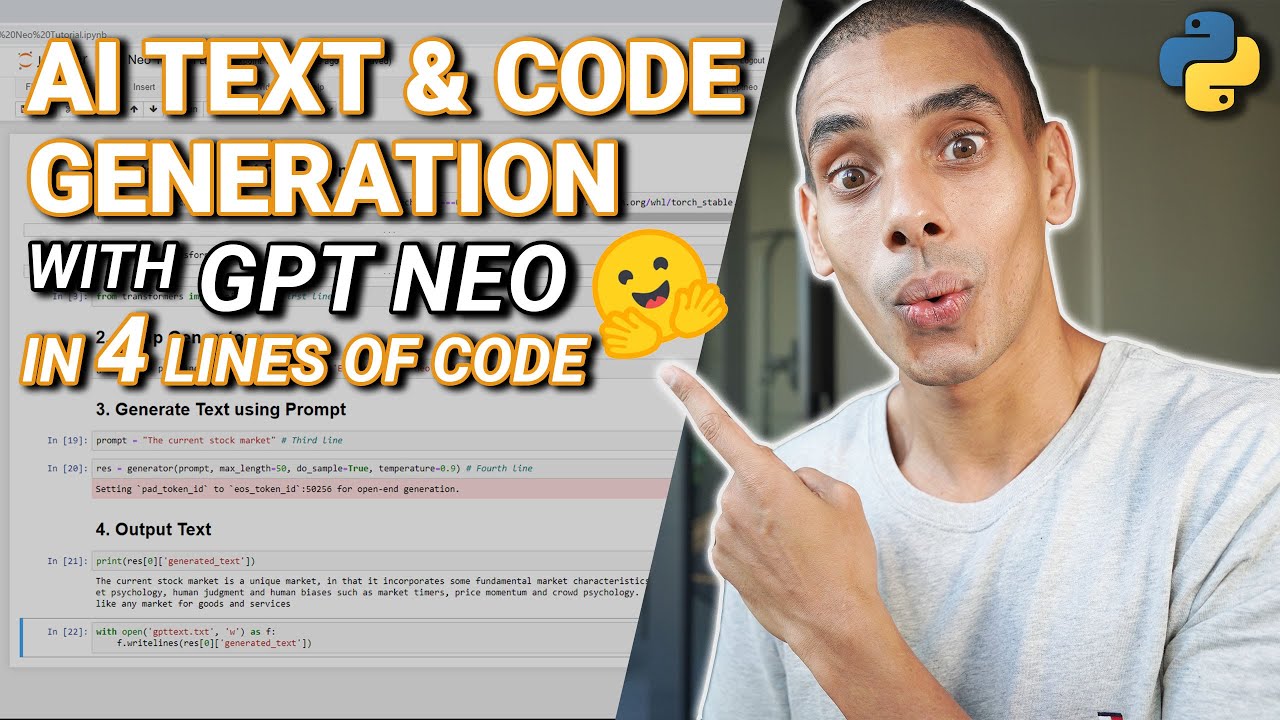
In this video, you’ll learn how to leverage GPT Neo, a GPT3 architecture clone, which has been trained on 2.7 BILLION parameters to generate text and code. You’ll learn how to get setup and leverage the model for a whole range of use cases in just 4 lines of code!
In this video you’ll learn how to:
1. Install GPT Neo a 2.7B Parameter Language Model
2. Generate Python Code using GPT Neo
3. Generate text using GPT Neo and Hugging Face Transformers
GET THE CODE FROM THE VIDEO: https://github.com/nicknochnack/GPTNeo
Code from the previous tutorial:
https://github.com/nicknochnack/MediaPipeHandPose
Chapters:
0:00 – Start
1:15 – How it Works
2:45 – Install PyTorch and Transformers
5:08 – Setup GPT Neo Pipeline
8:08 – Generate Text from a Prompt
14:46 – Export Text to File
17:48 – Wrap Up
Oh, and don’t forget to connect with me!
LinkedIn: https://bit.ly/324Epgo
Facebook: https://bit.ly/3mB1sZD
GitHub: https://bit.ly/3mDJllD
Patreon: https://bit.ly/2OCn3UW
Join the Discussion on Discord: https://bit.ly/3dQiZsV
Happy coding!
Nick
P.s. Let me know how you go and drop a comment if you need a hand!