
codebasics
Credit card fraud detection, cancer prediction, customer churn prediction are some of the examples where you might get an imbalanced dataset. Training a model on imbalanced dataset requires making certain adjustments otherwise the model will not perform as per your expectations. In this video I am discussing various techniques to handle imbalanced dataset in machine learning. I also have a python code that demonstrates these different techniques. In the end there is an exercise for you to solve along with a solution link.
Code: https://github.com/codebasics/deep-learning-keras-tf-tutorial/blob/master/14_imbalanced/handling_imbalanced_data.ipynb
Path for csv file: https://github.com/codebasics/deep-learning-keras-tf-tutorial/blob/master/14_imbalanced
Exercise: https://github.com/codebasics/deep-learning-keras-tf-tutorial/blob/master/14_imbalanced/handling_imbalanced_data_exercise.md
Focal loss article: https://medium.com/analytics-vidhya/how-focal-loss-fixes-the-class-imbalance-problem-in-object-detection-3d2e1c4da8d7#:~:text=Focal%20loss%20is%20very%20useful,is%20simple%20and%20highly%20effective.
#imbalanceddataset #imbalanceddatasetinmachinelearning #smotetechnique #deeplearning #imbalanceddatamachinelearning
Topics
00:00 Overview
00:01 Handle imbalance using under sampling
02:05 Oversampling (blind copy)
02:35 Oversampling (SMOTE)
03:00 Ensemble
03:39 Focal loss
04:47 Python coding starts
07:56 Code – undersamping
14:31 Code – oversampling (blind copy)
19:47 Code – oversampling (SMOTE)
24:26 Code – Ensemble
35:48 Exercise
Do you want to learn technology from me? Check https://codebasics.io/?utm_source=description&utm_medium=yt&utm_campaign=description&utm_id=description for my affordable video courses.
Previous video: https://www.youtube.com/watch?v=lcI8ukTUEbo&list=PLeo1K3hjS3uu7CxAacxVndI4bE_o3BDtO&index=20
Deep learning playlist: https://www.youtube.com/playlist?list=PLeo1K3hjS3uu7CxAacxVndI4bE_o3BDtO
Machine learning playlist : https://www.youtube.com/playlist?list=PLeo1K3hjS3uvCeTYTeyfe0-rN5r8zn9rw
🌎 My Website For Video Courses: https://codebasics.io/?utm_source=description&utm_medium=yt&utm_campaign=description&utm_id=description
Need help building software or data analytics and AI solutions? My company https://www.atliq.com/ can help. Click on the Contact button on that website.
#️⃣ Social Media #️⃣
🔗 Discord: https://discord.gg/r42Kbuk
📸 Dhaval’s Personal Instagram: https://www.instagram.com/dhavalsays/
📸 Instagram: https://www.instagram.com/codebasicshub/
🔊 Facebook: https://www.facebook.com/codebasicshub
📝 Linkedin (Personal): https://www.linkedin.com/in/dhavalsays/
📝 Linkedin (Codebasics): https://www.linkedin.com/company/codebasics/
📱 Twitter: https://twitter.com/codebasicshub
🔗 Patreon: https://www.patreon.com/codebasics?fan_landing=true
DISCLAIMER: All opinions expressed in this video are of my own and not that of my employers’.
Source

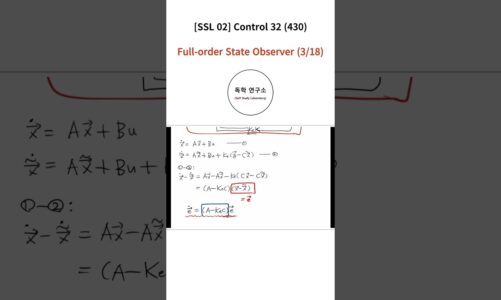

Check out our premium machine learning course with 2 Industry projects: https://codebasics.io/courses/machine-learning-for-data-science-beginners-to-advanced
please comment what if…… we pass different datasets…..on classification models….i got less accuracy..and model was build on different datasets…….but new datasets are different distribution,size….how to solve this problem…to improve performances ……….what should you do next….
one more question suppose we build a model fraud detection based on datasets….like 40% defaulter and 60% non defaulter…….what happend if we passed different datsets ,different distribution…diffrent size,quality……new datsets approx…70% deafulter 30 % non defaulter………so how we can overcome this problem………we build two models ,we combine two datsets….to build one model…..plz commnet …
excellent approach very helpfull
Sir I had a python coding implementing deep neural.netowrk on Kdd dataset can.you explain the coding toe in.a.gmeet session forever I will be.indebted to you thmq
Thank you so much. It was very informative.
Hey Dhaval. Great Video however I have a question. Will using class_weight parameter in Tensorflow and assigning the values based on the occurrence of the classes create any sort of bias towards some classes?? Can class_weight be helpful for handling the imbalance and not doing any sampling of any kind??
Great stuff, but an error I believe. AT 31:07, in the ensemble method, you've used the function 'get_train_batch' to get X_train and y_train, but you're not redefining X_test and y_test
JUST THE BEST
nice video, pretty clear. I think there are 2 things that are missing though:
1) Doing the under/oversampling only on training data
2) You could have also choose a different operating point (instead of np.round(y_pred), taking a different threshold) , or just using AUC measure and not rounding at all, that could have been more indicative
PS: SMOTE don't actually give any lift in AUC measure. you off just as well adjusted the threshold to y_pred>0.35 or something like that and get better F1 scores
Thank you for your sharing.
Thank you sir
Really helpful. Could you please tell whether oversampling strategy is okay if we do cross-validation instead of train-test-split?
does this approach work for more than 2 categories in Target variable?
Wonderful video. Great effort. Thank you.
Tremendous respect sir, I love your tutorial. I sincerely follow your tutorial and practice all exercises that you provide. However, I went through some comments for this video lecture and found that people are suggesting to oversample/SMOTE the training sample only, and not to disturb the test sample (which I too believe is quite apparent, as this will avoid duplicate or redundant entry in training and test data set). Hence, separated out the train and test datasets first, then applied the oversample/SMOTE technique on the training dataset only. Unfortunately, the precision, recall, and f1-score are not increasing for the minority class. This is quite logical though. What I understood is, duplicate entry of the same sample in both the train and test dataset was the reason for that huge increase in minority class precision, recall, and f1-score in your case.
In my opinion the SMOTE part is not wrong, but it is tricky. Using SMOTE on the entire dataset will make the X_test performance much better for sure since it will predict values already seen. Instead, if you split your data before the SMOTE you can see that the performance improves, but not too much, it will not reach 0.8 if without SMOTE was 0.47. The X_test in the video could probably interpreted as the X_validation, and the testing data should be imported from other sources, or at the beginning the dataset should be divided into training and test, like on Kaggle.
Hi! Why dont directly use the train_test_split with the stratify argument? Thank u!
awesome
can you guide to setup gpu for tensor?
can anyone give a solution of SMOTE memory allocation error problem. maybe many of u say that use premium GPU but it's too costly. Is there any other solution for solving this problem??
Can we use variational auto encoder for synthetic data generation in case of minority class?
Very interesting, amazing video…at 22:34 when using SMOTE method , smote.fit_sample(X,y) is now smote.fit_resample(X,y).
Thank you again Dhaval. I really appreciate your efforts!!
ITS FIT_RESAMPLE(X,y)
IN
from imblearn.over_sampling import SMOTE
smote = SMOTE(sampling_strategy='minority')
X_sm, y_sm = smote.fit_sample(X, y)
y_sm.value_counts()
Its a great tutorial! But i have a comment in the evaluation part. you applied Resampling first before splitting the data. So its possible that there's a leakage of data coming from the training to the test set. Right? thats why it has a equal prediction score. Its a good technique that you should split the data set first and then resample only the training set. Hope this helps. Thanks
The way you are introducing the information is very very excellent, thanks for sharing your knowledge and I'm happy to watch your video
THAT LAUGH AT 22:40……..
hello, Sir , I tried this exercise….but for ensemble the f1 score did not change much….for individual batches f1 score for both 0 and 1 was around.80 and .50……and it hardly chaNGED for overall..
Is it the same process in multi label classification ?
ew
thanks for these good vide
os these are very help full for me
00:00 Overview
00:01 Handle imbalance using under
sampling
02:05 Oversampling (blind copy)
02:35 Oversampling (SMOTE)
03:00 Ensemble
03:39 Focal loss
04:47 Python coding starts
07:56 Code – undersamping
14:31 Code – oversampling (blind copy)
19:47 Code – oversampling (SMOTE)
24:26 Code – Ensemble
35:48 Exercise
I think the test train split should be done before under or oversampling. Otherwise, the results are not reliable.
how can i balance , if there are 3 classes?
thank you sir
The link in the first exercise (this notebook) is giving error.
why you using weights= -1 ?
Which is the Best method to do the sampling before Spiting the dataset or After Splitting the dataset
the evil laugh at 22:28 😂😂
I am getting error Failed to convert a NumPy array to a Tensor (Unsupported object type int).
So fun the laugh at 22:31 hehe really cool video!
Can we apply same technique if we have more than 2 classes?
Thanks!
31:40 the ANN function is using the same old X_test and y_test. I think that's why the accuracy is so bad.
Undersampling 7:34
Oversampling 15:04
I think in case of undersampling and oversampling variable naming should habe been df_train_under and df_train_over, we should applying these on train dataset, not on test, i think sir has missed that point, applying sampling on entire dataset is useless