The A.I. Hacker – Michael Phi
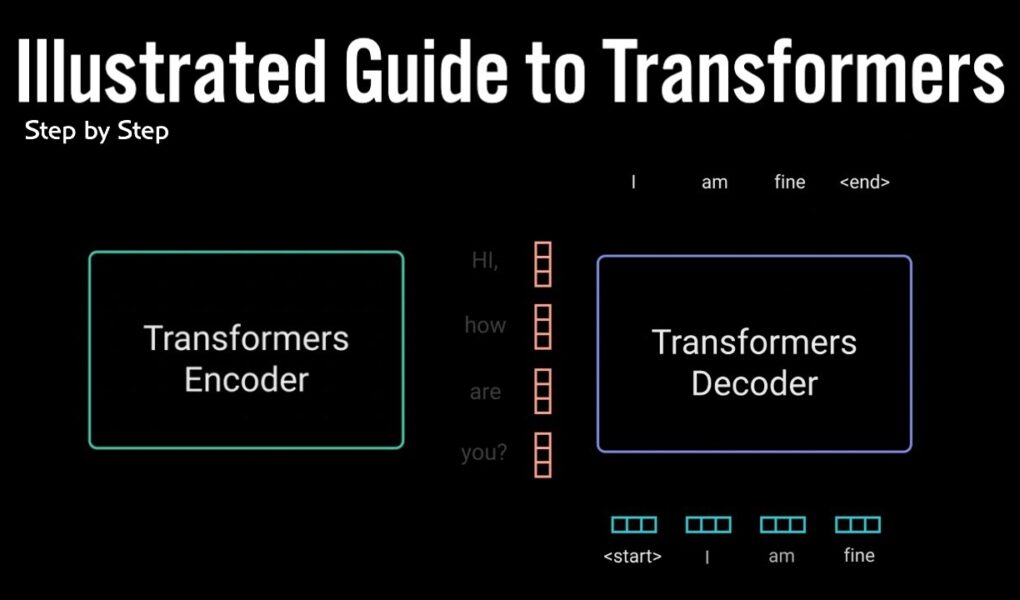
Transformers are the rage nowadays, but how do they work? This video demystifies the novel neural network architecture with step by step explanation and illustrations on how transformers work.
CORRECTIONS:
The sine and cosine functions are actually applied to the embedding dimensions and time steps!
⭐ Play and Experiment With the Latest AI Technologies at https://grandline.ai ⭐
Hugging Face Write with Transformers
https://transformer.huggingface.co/
Source



https://www.youtube.com/watch?v=zWNrjZXKOtU
bro you conciiiiiiiiise! Thank you for this!!!
The Sal Khan of Deep Learning! Thank you
is there a small mistake in the graphical explaination in 4:45? could you clearify this?
The graph seems to have an inconsistency in the representation of the positional encodings for the different time steps, based on your description. In a correctly implemented positional encoding applied to a transformer model, the values for sine and cosine alternate in successive dimensions of the positional encoding vector, not in successive time steps. This means that each element in the sequence is given the same encoding vector, with the values differing only by the position (pos), not by the points in time (time steps).
at 10:50 you jump into outputs but you don't explain where these come from… the way you explain it it sounds like they just appear out of thin air… so …
Better than statquest. He over complicated it.
This is more of a Description, than an Explanation. Simply describing a diagram and naming the blocks is not necessarily helpful.. Anyone else here completely confused, don't dismay. I'm a software engineer with experience in some other machine learning algorithms, and couldn't make much sense of any of this.
Thanks great explanation.
5:26
omg you save my seminar😇😇😇it is very great explanation!!!!!!
when there's layerNorm( … + …) is it pointwise + or concatenation inside LayerNorm argument?
A complex process- I need to listen to this multiple times to fully understand this.
can you do it again, but next time slower.
What software was used to create the presentation?
I can't thank you enough for this great video!!
Amazing. I still don’t really understand how the Q K and V values are calculated but I learnt a lot more about this seminal paper than others provided — thank you! 🙏
GPT stands for Generative Pre-training Transformer, not Pre-Training.
This was helpful! Thank you!
In 7:27, In the right the attention wieghts is a 4*4matrix while value matrix is 3*4, a 4*3 matrix for value will be more appropriate
THE OPTIMUM PRIDE?????!!!!!! OOO EEAHH OOEEAHAH
souldnt it be a 3*3 matrix (ie corresponding to the length of the vector )
great content
amazing explanation, honestly this is the first time i understand how Transformers work.
Best explanation I've seen – thanks !
Amazing vid
Watching this video after 3 year, i would say this is best till today
Hi, could you please explain more about the words at 13:07 (about step 6)? You said 'the process matches the encoder input to the decoder input allowing the decoder to decide which encoder input is relevant to put focus on'. So are you meaning that there are not only one but more encoders whose outputs will be parallely inputted to the decoders?
do they detect audio deepfake?
This seems to be one of the best videos on Transformers
great explanation
Need more math to properly understand what's going on
This explanation is INCREDIBLE!!!
You have such a sweet and pleasant voice. Thank you, mate, for the good explanation. 😊
Why does the decoder select the token with the maximum probability instead of randomly selecting a token based on the probability distribution?
看進步健康情形不僅是看不見卡巴斯基開心吧就是