Brandon Rohrer
Part of the End-to-End Machine Learning School course library at http://e2eml.school
Find the rest of the How Neural Networks Work video series in this free online course:
https://end-to-end-machine-learning.teachable.com/p/how-deep-neural-networks-work
A gentle walk through how they work and how they are useful.
Some other helpful resources:
RNN and LSTM slides: http://bit.ly/2sO00ZC
Luis Serrano’s Friendly Intro to RNNs: https://youtu.be/UNmqTiOnRfg
How neural networks work video: https://youtu.be/ILsA4nyG7I0
Chris Olah’s tutorial: http://bit.ly/2seO9VI
Andrej Karpathy’s blog post: http://bit.ly/1K610Ie
Andrej Karpathy’s RNN code: http://bit.ly/1TNCiT9
Andrej Karpathy’s CS231n lecture: http://bit.ly/2tijgQ9
DeepLearning4J tutorial: https://deeplearning4j.org/lstm
RNN/LSTM blog post: https://brohrer.github.io/how_rnn_lstm_work.html
Data Science and Robots blog: https://brohrer.github.io/blog.html
Follow me for announcements: https://twitter.com/_brohrer_
Source



Excellent explanation of LSTM in a very simplified and realistic way… Great video!
thank you bro
Thanks a lot for making everything so simple to understand, which in fact we find it very difficult to understand
Is RRN a replacement of Hidden Markov Model?
Best explanation, Thanks a lot. one cannot understand with text and math so easily. Great and nice work!
Amazing explanation. Thank you very much!
I heard minecraft spider at 19:01
Awesome video indeed. Very abstract concepts explained in very straightforward visual figures. Really appreciate it.
thank you!
well explanation, good for the one who getting start with machine learning and neuron network.
amazing!
4:30 "it's Tuesday" -> Takes some Nasal Spray? 😀 Anyone else noticed?
Great video, btw. Still watching but you'll probably end up saving my ass <3
This was fantastic, thank you so much for taking the effort to do all of this, it has really helped me get started.
Thank You, great video
What type of LSTM is he explaining?! It seems somehow different from the standard version of LSTM where there are two bus of information. It's something like GRU. The explanation of LSTM was more simpler, but it was also good.
I love You man, great video
Brilliant video! Thanks!!
As a complete newbie to NN, your explanation of both RNN and LSTM was amazing! However, a couple of question are still unsolved:
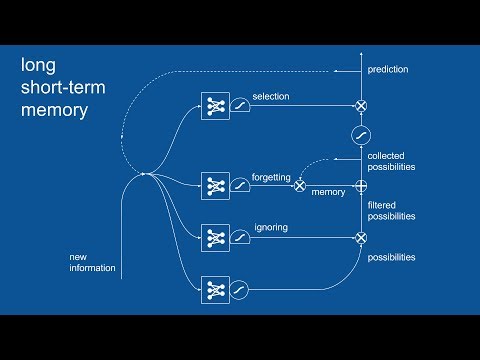
1. What does the ignoring gate do concretely? I suppose that, if the initial NN predicted 'Jane'/'Spot'/'.' the ignoring NN would stop the '.' from going through. But if the initial NN is trained like in the example of the video, the ignoring gate would be useless all the time…
2. I suppose that the selection gate did nothing in the video because the prediction had only 2 elements. Its effect would be noticeable if there were 100 elements and the selection gate would only let through ~ 10 of them?
3. This may be a dumb question, but… If all NN receive the same input (previous prediction + new input), the only way to get different results would be the initial random state, right? How can they play their role, if the inputs and the NN type are the same?
4. Finally, I checked Chris Olah's tutorial and I saw that the diagrams differ. In particular, the names differ: going by chronological order, your "ignoring" gate would be Chris' "forgetting" one, your "forgetting" would be Chris' "input" and finally your "selection" would be Chris' "output". Is it right? Also, in your diagram the prediction that will become the output is squished by the tanh function and gated, while Chris' is untouched (tanh and gate are only present in what is feeded in the next iteration of the LSTM).
Hope you can clarify some of my doubts, and thank you again for this video!
Its best and still i dont get it
Shit
best, bestttt where have you been man?
Thank you!
Yes, this is the best LSTM video on YouTube. Today is 27th July 2019.
This was a great video for a beginner like me. Thanks a lot !! Looking forward seeing more videos like these.
I'm preparing my university exam about "Data Science and machine learning", these videos are pure gold for someone who is approaching this topics for the first time like me. Thank you so much, it was really worth the time spent to watch it.
That was a fantastic explanation, video, and LSTM example. Thank you! Also, cool beard : )
Dwight Schrute imposter dictionary: {Bears, Beets, Battlestar Galactica, .}
Mistakes a Dwight Schrute imposter RNN can make:
"Bears. Beets. Battlestar Galactica."
Please make the Same video about Transformers neural network
Sorry to say that, Karpathy's lecture notes, particularly the alien language, bring me the worst study experience in ML.
Brandon has applied extraordinary skills in communicating the difficult (convoluted?) topic and concepts on LSTM, in simple and comprehensible language. The example on writing the "Children Text Book" brings out all of the major processes into sharp focus. I have learnt immensely. I will now be studying other videos by Brandon. Thanks a lot.
this video needs to be more popular. ;–; thankyou sir
Hi Brandon, @8:59, a RNN is cell shown. what is in the small square, is it again a NN or just a single layer? Similar question regarding lot of small squares used in LSTM cell @17:30